Inhalt
- Wo findet Ihr Crawling-Fehler in der Google Search Console und wie spürt Ihr diese auf?
- Crawling-Fehler-Typen
- Analyse von 404-Fehlern
- Analyse von Crawling-Problemen mit dem URL-Prüftool
- Fazit
Crawling-Fehler treten auf, wenn Google-Bots keinen Zugriff auf einzelne URLs oder Eure gesamte Website haben. Ursachen dafür können fehlerhafte Server-Einstellungen, CMS-Fehler oder Änderungen in der URL-Struktur sein. Mit der Google Search Console könnt Ihr diese Crawling-Fehler einfach finden und beheben. Welche Crawling-Fehler das sind, wie Ihr sie mithilfe der Google Search Console findet und anschließend beheben könnt, erfahrt Ihr in diesem Artikel.
Wo findet Ihr Crawling-Fehler in der Google Search Console und wie spürt Ihr diese auf?
Sobald Ihr Euch in die
Google Search Console eingeloggt habt, klickt Ihr einfach auf „Seiten“ unter dem Abschnitt „Indexierung“.
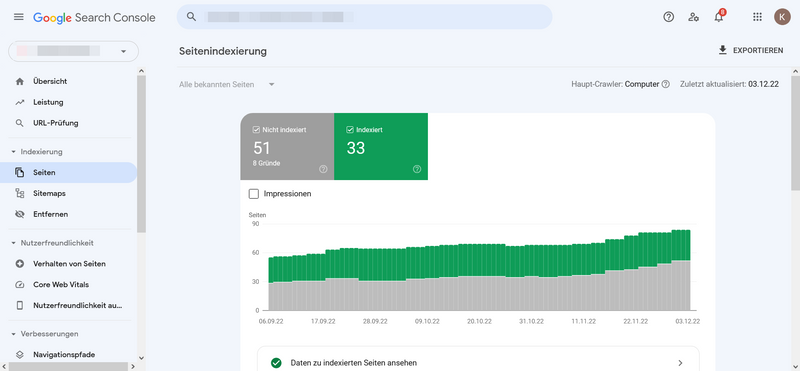
Seitenindexierung
Die erste Auswertung zeigt, wie viele Eurer Seiten indexiert sind und wie viele nicht. Scrollt Ihr nach unten, seht Ihr einen Crawling-Fehlerbericht mit einer Auflistung der Gründe, wieso Seiten nicht indexiert wurden und wie viele Seiten von diesem Crawling-Fehler betroffen sind.
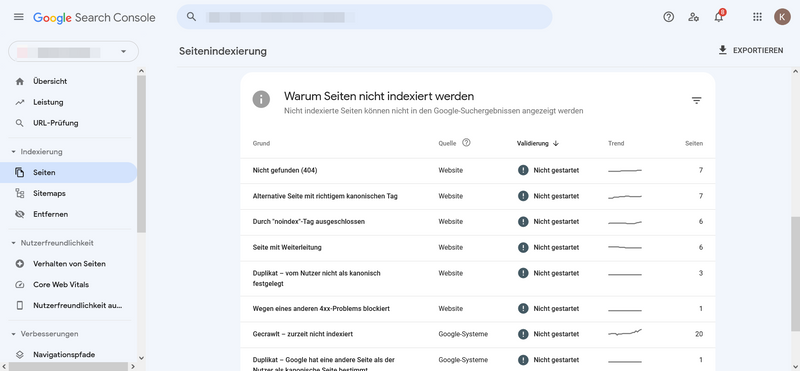
Übersicht Crawling-Fehlerbericht
Nun könnt Ihr durch einen weiteren Klick auf den Crawling-Fehler alle betroffenen URLs sehen.
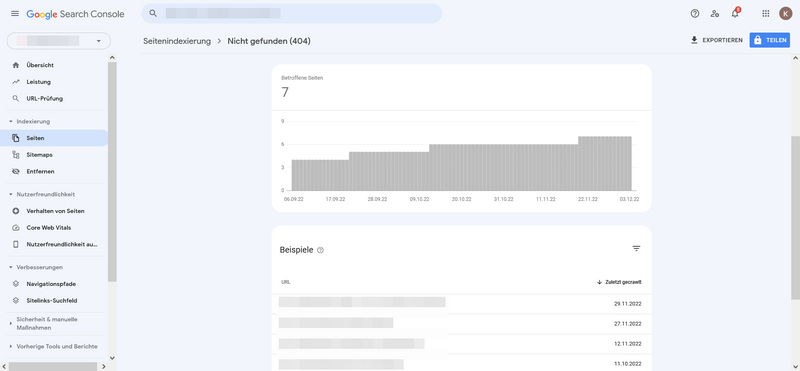
Crawling-Fehler alle betroffenen URLs
Im Seitenmenü unter „Einstellungen“ habt Ihr außerdem die Möglichkeit, Eure Crawling-Statistik einzusehen. Alle Statistiken beziehen sich immer auf die letzten 90 Tage.
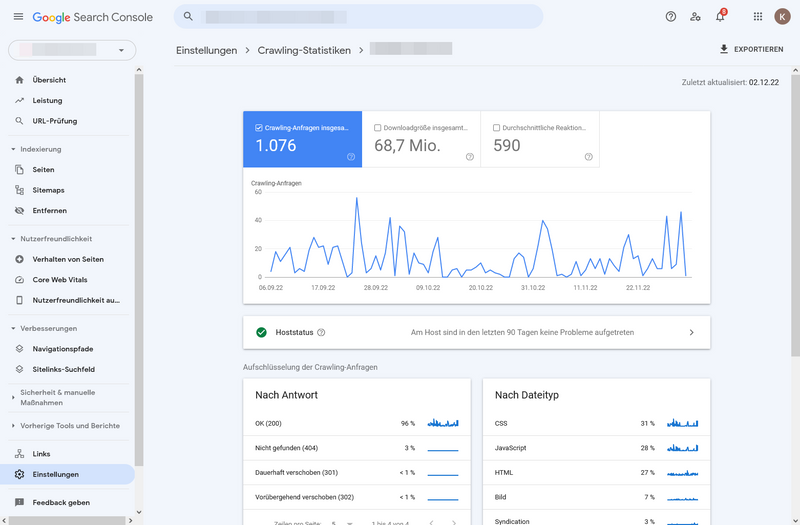
Crawling-Statistiken unter Einstellungen
Ein Hoststatus mit grünem Häkchen ist sehr gut, denn das bedeutet, in den vergangenen 90 Tagen sind keine schwerwiegenden Probleme aufgetreten:
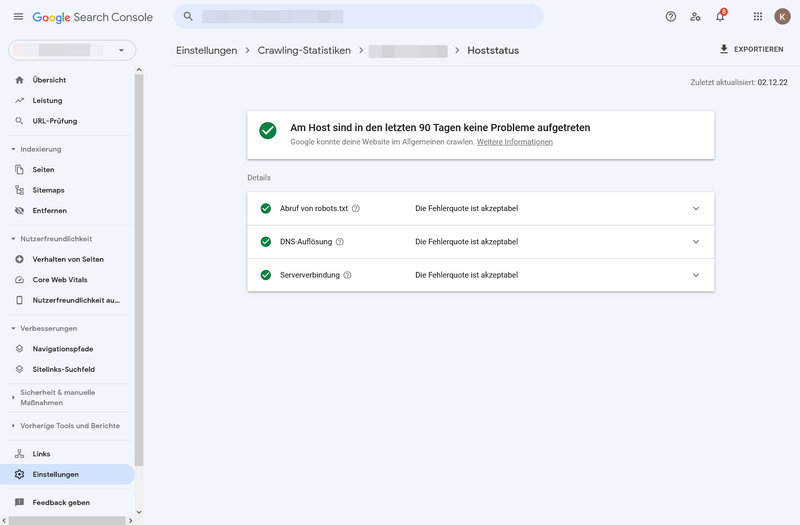
Übersicht Hoststatus
Crawling-Fehler-Typen
Es gibt zwei Arten von Crawling-Fehlern, die Ihr im Abschnitt zuvor bereits gesehen habt: Site-Errors und URL-Errors. Site-Fehler sind gravierend, da bei diesen Fehlern Eure gesamte Website nicht gecrawlt werden kann. Das bedeutet, Eure Website wird in Suchmaschinen nicht gefunden. URL-Fehler sind dagegen recht harmlos. Bei URL-Fehlern kann eine bestimmte Seite nicht gecrawlt werden. Das sind meist Crawling-Fehler, die sich einfach lösen lassen. Schauen wir uns beide Arten genauer an.
Site Error
DNS Error
DNS steht für Domain-Name-System. Zeigt Euch die Google Search Console diesen Fehler an, ist Eure Website nicht erreichbar. Das kann eine vorübergehende Störung sein. Die Google-Bots crawlen Eure Website in diesem Fall nach einer Weile erneut. Bleibt das Problem bestehen, ist die Wahrscheinlichkeit hoch, dass Euer Domain-Provider für das Problem verantwortlich ist. Kontaktiert diesen, um das Problem beheben zu lassen.
Server Error
Bei einem Server-Fehler benötigt Euer Server zu lange, um zu antworten. Der Crawler versucht, Eure Website zu erreichen, aber die Ladezeit ist zu lang. Im Gegensatz zum DNS Error kann Google Eure Website theoretisch aufrufen. Eine mögliche Ursache ist die Überlastung Eurer Website durch zu viele gleichzeitige Anfragen.
Robots Failure
Dieser Fehler tritt auf, wenn die Google-Bots die robots.txt-Datei Eurer Website nicht erreichen können. Die Datei benötigt Ihr nur, wenn Ihr bestimmte Seiten auf Eurer Website vom Crawling ausschließen wollt. Ist die Datei fehlerhaft und enthält die Zeile „disallow: /“, macht das Eure gesamte Website für Google-Bots unzugänglich.
URL Error
Nicht gefunden (404)
Eine in Eurer Sitemap enthaltene URL kann nicht auf dem Webserver gefunden werden. Ihr habt die Seite wahrscheinlich gelöscht oder die URL verlegt.
Soft 404-Fehler
Soft 404-Fehler treten bspw. auf, wenn die Seite für Google-Bots zwar erreichbar ist, aber sehr wenig Inhalt enthält. Auch eine Weiterleitung zu einer Seite, die sich thematisch von der vorherigen unterscheidet, wird von Google als Soft 404-Fehler eingestuft.
Zugriff verweigert (403)
Google-Bots können nicht auf den Inhalt zugreifen. Das kann mehrere Ursachen haben: Die Seite wird von Eurem Hosting-Provider oder Eurer robots.txt-Datei blockiert oder Ihr selbst legt fest, dass nur angemeldete Benutzer*innen die Seite aufrufen dürfen.
Wegen eines anderen 4xx-Problems blockiert
Der Server ist auf einen 4xx-Fehler gestoßen, der von keinem anderen hier beschriebenen 4xx-Fehler abgedeckt wird. Verwendet das Tool zur URL-Prüfung, um die Seite genauer zu untersuchen.
Weiterleitungsfehler
Wenn Ihr eine Seite auf Eurer Website verschiebt oder entfernt, solltet Ihr eine 301-Weiterleitung einrichten. Leitet Ihr mehrfach weiter oder zurück an den ursprünglichen Ort, können Fehler auftreten.
Durch "noindex"-Tag ausgeschlossen
Eure Seite wurde zur Indexierung eingereicht, enthält in einem Meta-Tag oder dem HTTP-Header eine „noindex“-Anweisung. Damit sendet Ihr Google widersprüchliche Signale. Soll die Seite indexiert werden, müsst Ihr einfach die „noindex“-Anweisung entfernen.
Duplikat – vom Nutzer nicht als kanonisch festgelegt
Der Google-Bot hat mehrere Versionen der Seite gefunden. Keine der Seiten hat ein bestimmtes kanonisches Tag. Der Google-Bot beschließt dann selbst, diese Seite nicht als die primäre Seite zu sehen und schließt sie von der Indexierung aus.
Duplikat – Google hat eine andere Seite als die Nutzer*innen als kanonische Seite bestimmt
Diese Fehlermeldung ähnelt der vorherigen. Der Unterschied ist, dass Ihr hier eine Indexierung angefragt habt. Google ist aber der Meinung, eine andere Seite sollte das kanonische Tag haben.
Gecrawlt – zurzeit nicht indexiert
Die URL wurde bereits gecrawlt, aber noch nicht indexiert. Das kann sehr viele Ursachen haben. Schaut am besten in der Google Search Console jeden einzelnen Treffer mit der URL-Prüfung an.
Gefunden – zurzeit nicht indexiert
Google-Bots haben die Seite gefunden, aber nicht gecrawlt. Der Versuch, die Seite zu crawlen, hätte zu einer Überlastung dieser geführt. Google wird versuchen, die Seite erneut zu crawlen.
Nicht alle Fehler müssen unbedingt behoben werden. Wichtig ist aber, dass Ihr Euch jede Fehlermeldung anschaut und anschließend entscheidet, ob Ihr handeln müsst oder nicht.
Analyse von 404-Fehlern
404-Fehler sind sehr vielfältig. Erst einmal bedeutet es nur, dass der Google-Bot eine Seite nicht finden kann. Das wirkt sich nicht negativ auf die Performance Eurer Website aus. Meist existiert die Seite entweder nicht mehr an einem Ort, der für den Bot zugänglich ist oder die Seite hat keinen erwähnenswerten Inhalt mehr. 404-Fehler treten häufig auf, da Eure Website wächst und sich verändert. Nicht immer müsst Ihr aktiv werden und den Fehler beheben. Schauen wir uns die Gründe und Lösungen für 404-Fehler mal genauer an.
1. URL geändert
Ihr habt den Link einer Seite geändert, aber vergessen, eine Weiterleitung zur neuen Seite einzurichten. Das solltet Ihr nachholen, damit Besucher*innen nicht auf der 404-Seite landen und der Website-Traffic ins Leere geht. Für WordPress gibt es Plug-ins, die automatisiert Weiterleitungen erstellen können.
2. Inhalt geändert oder gelöscht
Die Seite wurde indexiert, jetzt befindet sich aber kein oder kaum Inhalt mehr auf der Seite. Da die Seite aber erreichbar ist, ist es eine Sonderform des 404-Fehlers. Die gesendete URL erhält einen Soft 404-Fehler zurück. Wenn die Seite nicht mehr verfügbar ist und Ihr die Inhalte auch nirgends sonst habt, konfiguriert den Server so, dass er einen 404 (nicht gefunden) oder 410 (nicht mehr vorhanden) Antwortcode zurückgibt. Versucht außerdem, alle Links, die auf diese Seite führen, zu löschen. Befinden sich Verlinkungen auch außerhalb Eurer Website, bittet die Verantwortlichen, den Link zu entfernen.
3. URL falsch
Hier liegt der Fehler nicht zwangsläufig bei Euch, sondern vielleicht bei den Surfenden. Geben sie eine URL falsch ein, landen sie auf einer 404-Seite. Bei Euch erscheint die gesuchte URL dann im Crawling-Fehlerbericht. Habt Ihr bspw. eine Website für E-Gitarren und die Surfenden suchen nach „Seiten“ anstelle von „Saiten“, werden sie nicht fündig. Außer: Ihr kennt die falsch eingegebenen URLs und richtet eine Weiterleitung ein. Es kann auch passieren, dass Ihr Euch bei einer Verlinkung vertippt habt. Diesen Fehler könnt Ihr leicht korrigieren.
4. Links in eingebetteten Inhalten
Google-Bots versuchen Links zu folgen, die sich in einem eingebetteten Inhalt befinden, bspw. in JavaScript. Diese URLs sind nicht Teil Eurer Website. Da es sich oft nicht um eine richtige Seite handelt, die entsprechend nicht aufgerufen werden kann, erhaltet Ihr eine Meldung im Crawling-Fehlerbericht. Diese könnt Ihr ignorieren.
Das Tool zur URL-Prüfung liefert Euch Informationen über eine von Google gecrawlte Seite. Ihr könnt testen, ob eine URL indexiert werden könnte. In der Google Search Console habt Ihr mehrere Möglichkeiten, zur URL-Prüfung zu gelangen. Möchtet Ihr eine Seite aus dem Crawling-Fehlerbericht prüfen, wählt Ihr einen Crawling-Fehler-Typ aus und gelangt zu der Fehler-Statistik mit allen Seiten, auf denen dieser Crawling-Fehler auftritt. Mit einem Klick auf eine URL unter „Beispiele“ schiebt sich seitlich ein Fenster ein mit der Option, die URL zu prüfen.
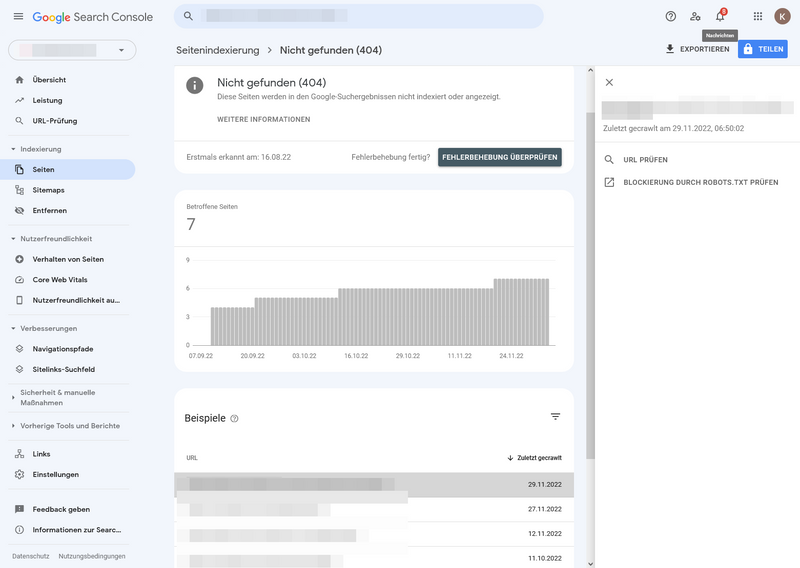
URL-Prüfung - Fehlerübersicht
Nach einem Klick auf „URL prüfen“ bekommt Ihr das Ergebnis der Prüfung.
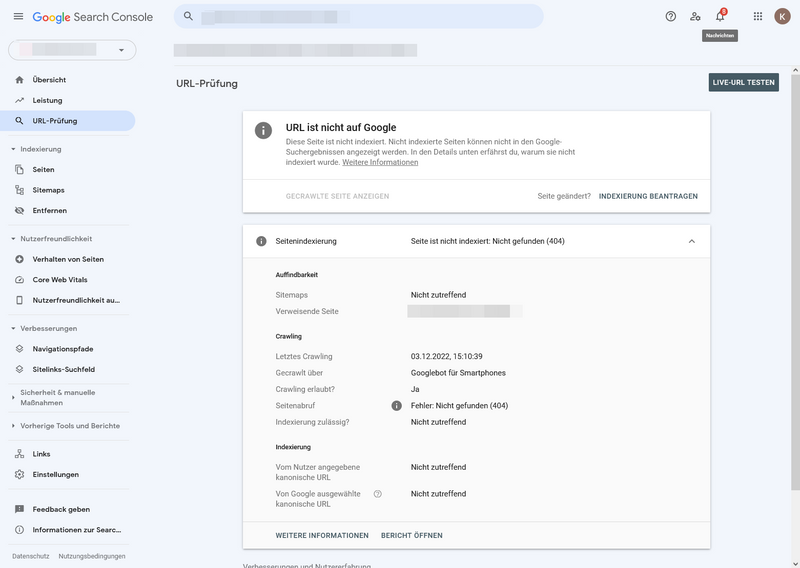
URL-Prüfbericht
Eine weitere Möglichkeit ist, die URL direkt in das Suchfeld oben im Tool einzugeben. Ihr erhaltet die gleiche Übersicht. Der Unterschied: Ihr könnt auch neue Seiten prüfen, die noch nicht gecrawlt wurden und mit einem Klick die Indexierung beantragen. Schauen wir uns die Bedeutung der einzelnen Abschnitte unter Seitenindexierung an:
- Auffindbarkeit: So hat Google Eure URL gefunden.
- Crawling: Ihr seht, ob Google Eure Seite crawlen konnte, wann sie gecrawlt wurde und welche Schwierigkeiten es dabei gab.
- Indexierung: Hier seht Ihr die kanonische URL, die Ihr und Google für diese Seite ausgewählt habt.
Fazit
Die Google Search Console ist ein sehr gutes Diagnose-Tool, um Crawling-Fehler zu finden und zu beheben. Einige Crawling-Fehler haben kaum bis keine Auswirkungen auf die Performance und Benutzerfreundlichkeit Eurer Seite. Andere erfordern sofortiges Handeln. Prüft daher regelmäßig, ob und welche Crawling-Fehler auf Eurer Website auftreten. Auf OMR Reviews gibt es eine Anleitung zur
Einrichtung der Google Search Console, um das
SEO-Tool bestmöglich zu nutzen.
Empfehlenswerte SEO Tools
Weitere empfehlenswerte SEO-Tools kannst du auf OMR Reviews finden und vergleichen. Insgesamt haben wir dort über 3400 SEO-Tools (Stand: Juni 2026) gelistet, die dir dabei helfen können, deinen organischen Traffic langfristig zu steigern. Also schau vorbei und vergleiche die Softwares mithilfe der verifizierten Nutzerbewertungen:
