Inhalt
- Datenschutz bei ChatGPT: die Basics
- Ist ChatGPT datenschutzkonform?
- So verhinderst du, dass ChatGPT deine Daten für Trainings nutzt
- Beispiele für rechtliche Probleme bei der Nutzung von ChatGPT
- KI-Verordnung der EU: Ein Schritt in die richtige Richtung?
- Drei Tipps für den sicheren Umgang mit ChatGPT
- Fazit: Viele Möglichkeiten, viele Risiken
ChatGPT dominiert die Landschaft der generativen KI-Tools und ist längst fester Bestandteil im beruflichen und privaten Alltag vieler Nutzer*innen: Laut dem Bayerischen Forschungsinstitut für Digitale Transformation (bidt) ist
ChatGPT mit 81 % die mit Abstand meistgenutzte KI-Anwendung. Doch dieser Popularitätsschub kommt nicht ohne Schattenseiten: Datenschützer*innen sehen die KI seit jeher kritisch. Der Grund: Das Tool von OpenAI verarbeitet massive Datenmengen.
Während Millionen von Nutzer*innen täglich ihre Anfragen an den Chatbot richten, bleibt oft unklar, was mit diesen Daten tatsächlich geschieht. Werden deine vertraulichen Geschäftsinformationen für das Training künftiger KI-Modelle verwendet? Kannst du das überhaupt verhindern? Und was passiert, wenn du versehentlich personenbezogene Daten Dritter eingibst?
In diesem Artikel erfährst du nicht nur, welche Daten
ChatGPT genau verarbeitet und wie OpenAI damit umgeht, sondern auch, welche konkreten Schritte du unternehmen kannst, um deine Privatsphäre zu schützen. Vom Opt-Out-Tutorial bis zu den wichtigsten Verhaltensregeln.
Das Wichtigste in Kürze
- ChatGPT verarbeitet eine Vielzahl von Daten, darunter Anfragen, Nutzerdaten und hochgeladene Dateien, die für das Training der KI genutzt werden können.
- Die Datenschutzkonformität von ChatGPT ist in rechtlicher Grauzone, insbesondere in Bezug auf die Verarbeitung personenbezogener Daten und die mangelnde Transparenz.
- Durch das Deaktivieren der „Modell für alle verbessern“-Option und die Nutzung von provisorischen Chats kannst du verhindern, dass deine Daten für zukünftige KI-Trainings verwendet werden.
- Wichtige rechtliche Probleme umfassen potenzielle Urheberrechts- und Datenschutzverletzungen, wie die unbewusste Nutzung von persönlichen Daten Dritter.
- Mit der EU-KI-Verordnung (AI Act) wird ein klarer rechtlicher Rahmen geschaffen, der auch Transparenz und Datenschutzanforderungen für KI-Modelle wie ChatGPT umfasst.
Datenschutz bei ChatGPT: die Basics
Hand aufs Herz: Du fragst ChatGPT täglich nach Rezepten, Programmcode oder Business-Strategien – aber hast du eine Ahnung, was mit all diesen Daten aus deinen Prompts passiert oder wem die Ergebnisse gehören?
Welche Daten werden von ChatGPT verarbeitet?
ChatGPT nutzt eine gewaltige Bandbreite an (persönlichen) Informationen. Dazu gehören deine Kontodaten (Name, E-Mail, Zahlungsinformationen), sämtliche Inhalte deiner Anfragen (Prompts) an ChatGPT sowie hochgeladene Dateien, Bilder und Audiodateien – je nachdem, welche Funktionen du nutzt.
Auch wenn du kein Konto erstellst, erfasst OpenAI automatisch technische Informationen wie IP-Adresse, Browsertyp, Gerätedaten und Standortinformationen. Diese Daten können durch Cookies und ähnliche Technologien über mehrere Browsersitzungen hinweg gespeichert werden.
Wie werden deine Daten genutzt?
Die von dir bereitgestellten Daten dienen zunächst dem offensichtlichen Zweck: der Beantwortung deiner Anfragen. OpenAI formuliert das auf seiner Website so: „Wenn du Inhalte mit uns teilst, hilft dies unseren Modellen, genauer zu werden und deine spezifischen Probleme besser zu lösen.“ Anders ausgedrückt bedeutet das: OpenAI verwendet deine Daten ausdrücklich zum Training seiner KI-Modelle – sofern du dem nicht aktiv widersprichst.
Darüber hinaus nutzt OpenAI deine Daten zur Verbesserung und Weiterentwicklung der Dienste, zur Kommunikation mit dir, zur Betrugsprävention und zum Schutz der Systemsicherheit. Wichtig: OpenAI erklärt, dass die Unternehmensdienste (API, ChatGPT Enterprise und ChatGPT Team) standardmäßig nicht für das Training der Modelle verwendet werden. Für kostenlose und Plus-Nutzer*innen gelten jedoch andere Regeln – hier musst du aktiv in deinen Einstellungen widersprechen, wenn du nicht möchtest, dass deine Daten zum Training verwendet werden.
Wem gehören die Ergebnisse, die ChatGPT produziert?
Bei der Frage nach den Eigentumsrechten an den von ChatGPT generierten Inhalten muss man zwischen Nutzungsrechten und dem Urheberrecht unterscheiden.
Vereinfacht gesagt, besitzt du zwar Nutzungsrechte an den Ergebnissen, aber kein Urheberrecht im klassischen Sinne. Die rechtliche Situation ist komplex und international nicht einheitlich geregelt. In vielen Ländern – so auch in Deutschland – gelten KI-generierte Inhalte als nicht urheberrechtlich schützbar, da ein menschlicher Schöpfungsakt fehlt.
Das hat weitreichende Konsequenzen: Jede*r kann theoretisch die von ChatGPT für dich erstellten Texte, Bilder oder Ideen verwenden. Überlege dir also gut, in welchem Rahmen du die Ergebnisse teilst, die die KI für dich generiert hat.
Du willst noch mehr zum Thema KI wissen? Dann schau doch auch in unsere anderen Artikel:
Die Datenschutzkonformität von ChatGPT bewegt sich in einer rechtlichen Grauzone, die Expert*innen weltweit vor erhebliche Herausforderungen stellt. Der Knackpunkt: ChatGPT und ähnliche KI-Systeme verarbeiten wie erwähnt massenhaft Daten – darunter häufig auch personenbezogene oder urheberrechtlich geschützte Inhalte – ohne Zustimmung der betroffenen Personen.
Die problematische Datenverarbeitung
Das zentrale Problem liegt im Trainingsansatz. OpenAI nutzt für das Training seiner Modelle Milliarden von Texten aus dem Internet, darunter Bücher, Artikel, Blogbeiträge und Social-Media-Inhalte. Wurden hierfür die erforderlichen Rechte eingeholt? Das bezweifeln zumindest viele Kritiker*innen.
Datenschützer*innen kritisieren zudem die fehlende Rechtsgrundlage für die Verarbeitung personenbezogener Daten. OpenAI beruft sich hierbei auf ein „berechtigtes Interesse“ an der Entwicklung seiner KI-Systeme – ein Argument, das europäische Aufsichtsbehörden zunehmend skeptisch betrachten.
Ein weiteres Problem: Transparenz. OpenAI gibt zwar an, keine personenbezogenen Daten aktiv zu suchen, doch die genauen Datenquellen und Trainingsprozesse bleiben weitgehend im Dunkeln. Für Betroffene ist es nahezu unmöglich nachzuvollziehen, ob und wie ihre Daten im Training verwendet wurden.
Der Italien-Fall: Ein Warnsignal
Die Problematik zeigte sich beispielhaft im März 2023, als die italienische Datenschutzbehörde (Garante per la protezione dei dati personali) ChatGPT landesweit sperrte. Die Behörde begründete diesen drastischen Schritt mit mehreren schwerwiegenden Verstößen:
Fehlende Informationen zur Datenverarbeitung
Mangelnde Rechtsgrundlage für das massenhafte Sammeln personenbezogener Daten
Unzureichender Schutz vor dem Zugriff Minderjähriger
Ungenauigkeiten bei der Verarbeitung personenbezogener Informationen
Nach intensiven Verhandlungen war ChatGPT im April 2023 nach einer Implementierung verbesserter Datenschutzmaßnahmen wieder in Italien verfügbar. Ähnliche Untersuchungen laufen inzwischen in zahlreichen EU-Ländern, darunter Deutschland, Frankreich und Spanien.
Bemerkenswert: Während ChatGPT nach Anpassungen wieder in Italien zugelassen wurde, bleibt das konkurrierende
KI-Modell Deepseek aus China weiterhin verboten.
So verhinderst du, dass ChatGPT deine Daten für Trainings nutzt
Du möchtest ausschließen, dass OpenAI deine Eingaben zum Training seines KI-Modells nutzt? Dann gehe wie folgt vor:
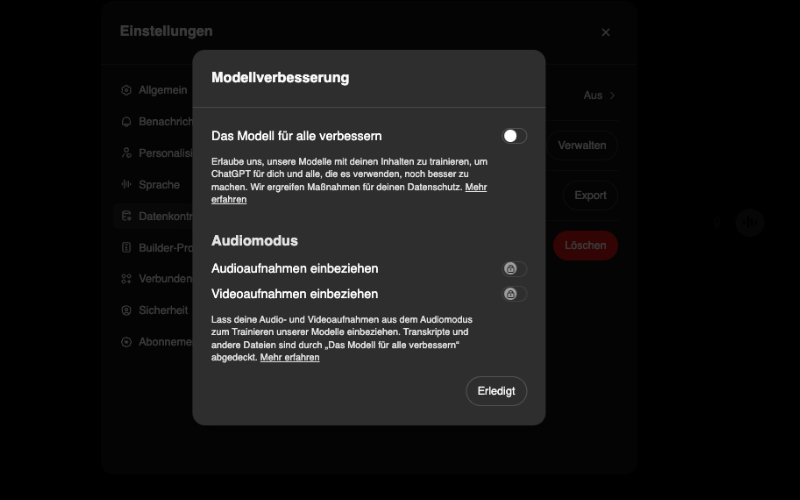
Die Einstellung für den Trainings-Opt-Out versteckt sich hinter der kryptischen Bezeichnung „Das Modell für alle verbessern“
Melde dich bei deinem ChatGPT-Konto an.
Klicke auf dein Profilbild in der oberen rechten Ecke.
Wähle „Einstellungen" aus dem Dropdown-Menü.
Navigiere zum Abschnitt „Datenkontrollen“.
Wähle hier den Menüpunkt „Das Modell für alle verbessern“.
Im nun geöffneten Untermenü kannst du die Verarbeitung deiner Daten für Trainingszwecke deaktivieren.
Nach dieser Änderung werden deine zukünftigen Gespräche nicht mehr zum Training der OpenAI-Modelle verwendet. Beachte jedoch: Bereits geführte Gespräche, die vor der Deaktivierung stattfanden, könnten bereits für Trainingszwecke genutzt worden sein.
Bonus-Tipp für mehr Datenschutz
Nutze die Funktion „Provisorischer Chat“ für besonders sensible Gespräche. Diese werden laut OpenAI grundsätzlich nicht für das Training verwendet, selbst wenn du das generelle Opt-Out nicht aktiviert hast. Temporäre Chats erscheinen nicht in deiner Chat-Historie und werden endgültig nach 30 Tagen gelöscht. Um einen provisorischen Chat zu starten, klickst du in ChatGPT einfach auf das gleichnamige Icon oben rechts neben deinem Profilbild.
Beispiele für rechtliche Probleme bei der Nutzung von ChatGPT
Die Datenschutzrisiken von KI-Tools wie ChatGPT sind keine theoretischen Bedrohungen – sie manifestieren sich bereits in konkreten Fällen, die erhebliche Konsequenzen nach sich ziehen. Zwei besonders relevante Beispiele zeigen, welche Risiken im Unternehmenskontext und bei der Nutzung kreativer Inhalte bestehen.
Studio Ghibli Memes
Im März 2025 veröffentlichte OpenAI ein Update für die
Bildgenerierung mit ChatGPT, wodurch man Zeichnungen im charakteristischen Stil des gefeierten Animationsstudios Studio Ghibli erzeugen konnte. Was als spielerisches Feature gedacht war, entwickelte sich schnell zu einem viralen Trend.
Innerhalb weniger Tage überschwemmten Ghibli-Style-Memes die sozialen Medien. Privatpersonen, Unternehmen und sogar politische Institutionen sprangen auf den Zug auf. Die Kontroverse folgte natürlich prompt: Obwohl Kunststile grundsätzlich nicht urheberrechtlich geschützt sind, stellte die massenhafte Aneignung eines so identifizierbaren Stils ohne Einwilligung oder Vergütung der Originalschöpfer*innen eine ethische Grauzone dar.
Der tiefere Datenschutzaspekt zeigte sich jedoch woanders: Nutzer*innen luden massenhaft persönliche Fotos hoch, um diese in „Ghibli-Versionen“ umzuwandeln – oft ohne Einwilligung der abgebildeten Personen. Diese Fotos wurden Teil des OpenAI-Datenpools und konnten potenziell für weiteres Training verwendet werden. Die Konsequenz: Eine großflächige, unbewusste Verletzung von Persönlichkeitsrechten durch gutgläubige Nutzer*innen.

Mit ausdrücklicher Genehmigung hat der Autor dieses Artikels ein Selfie für die Ghibli-Transformation genutzt – und schämt sich trotzdem ein wenig ob der ethischen Implikationen.
Samsung Leak
Noch brisanter als die Ghibli-Memes war der Samsung-Leak von 2023. Er gilt bis heute als Paradebeispiel für die Gefahren, die entstehen, wenn Mitarbeiter*innen KI-Tools ohne klare Richtlinien nutzen. Samsung-Angestellte gaben in nur 20 Tagen dreimal vertrauliche Unternehmensdaten in ChatGPT ein – darunter proprietären Quellcode und Halbleiter-Testmuster.
Die Mitarbeiter*innen wollten lediglich ihre Arbeit effizienter gestalten: Code optimieren, Präsentationen erstellen oder Fehler beheben. Sie übersahen dabei jedoch die fundamentale Tatsache, dass ihre Eingaben auf externen Servern gespeichert und potenziell zum Training verwendet wurden – ein klassischer Fall unbedachter Datenpreisgabe.
Samsungs Reaktion war drastisch: Das Unternehmen verbot umgehend die Nutzung von ChatGPT auf Firmengeräten, beschränkte die maximale Eingabelänge und begann mit der Entwicklung einer internen KI-Alternative. Die Ereignisse führten zu einer intensiven Debatte über „Conversational AI Leaks“ – ein neues Sicherheitsrisiko, das durch die alltägliche Nutzung von KI-Chatbots entsteht.
Der Fall verdeutlicht, wie schnell selbst technikaffine Mitarbeiter*innen die Datenschutzimplikationen ihrer Handlungen übersehen können. Er unterstreicht die Notwendigkeit klarer Unternehmensrichtlinien für den Umgang mit KI-Tools – und zeigt, dass die Bequemlichkeit dieser Tools oft mit erheblichen Datenschutzrisiken erkauft wird.
KI-Verordnung der EU: Ein Schritt in die richtige Richtung?
Der AI-Act beziehungsweise die
KI-Verordnung der EU stellt den weltweit ersten umfassenden Rechtsrahmen für künstliche Intelligenz dar. Veröffentlicht am 12. Juli 2024, trat er am 1. August 2024 in Kraft – ein Meilenstein für die Regulierung der KI-Technologie.
Zentrale Inhalte des AI Act
Die KI-Verordnung verfolgt einen klaren Ansatz: Sie will die Entwicklung und Nutzung menschenzentrierter KI in Europa fördern und gleichzeitig ein hohes Schutzniveau für unsere Gesundheit, Sicherheit und Grundrechte gewährleisten. Anders als viele befürchtet hatten, verbietet sie nicht pauschal KI-Anwendungen – vielmehr kategorisiert sie diese nach ihrem Risikopotenzial:
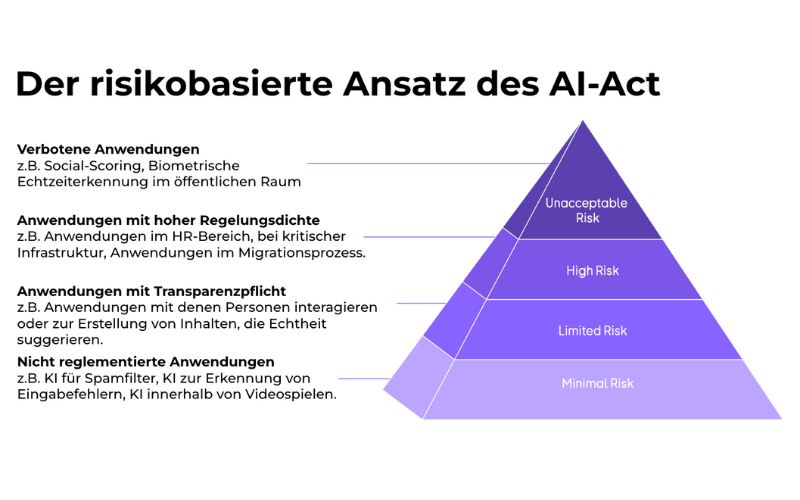
Der AI Act gliedert Anwendungen in vier Risikostufen – Infografik so erschienen in Stößer, F. (2025). „Rechtliche Fragestellungen zu KI“ [PowerPoint-Präsentation].
Zentrale Pflichten für Unternehmen
Für Anbieter*innen und Betreiber*innen von KI-Systemen – insbesondere von Hochrisiko-Systemen – entstehen durch die Verordnung umfangreiche Verpflichtungen:
Risikomanagement: Kontinuierliche Identifizierung und Minimierung von Risiken
Daten-Governance: Verwendung hochwertiger, repräsentativer Trainingsdaten
Transparenz: Umfassende Dokumentation und Informationspflichten
Menschliche Aufsicht: Sicherstellung effektiver menschlicher Kontrolle über KI-Entscheidungen
Robustheit: Gewährleistung der Genauigkeit und Cybersicherheit
Sanktionen bei Missachtung
Bei Verstößen drohen empfindliche Geldbußen, die je nach Schwere des Verstoßes und Größe des Unternehmens variieren:
Bis zu 35 Millionen Euro oder 7 % des weltweiten Jahresumsatzes für die schwerwiegendsten Verstöße
Bis zu 15 Millionen Euro oder 3 % des Jahresumsatzes für die Nichteinhaltung anderer Verpflichtungen
Bis zu 7,5 Millionen Euro oder 1,5 % des Jahresumsatzes für die Bereitstellung unrichtiger Informationen
Wo steht ChatGPT in der Gefahrenpyramide?
ChatGPT fällt als „KI-Modell mit allgemeinem Verwendungszweck“ unter spezielle Regelungen des AI-Acts. In seiner Standardform wird es nicht als Hochrisiko-KI eingestuft. Es könnte jedoch in bestimmten Anwendungskontexten als Hochrisiko-System gelten – etwa wenn es im Gesundheitswesen zur Diagnoseunterstützung, bei Kreditvergabeentscheidungen oder in der öffentlichen Verwaltung eingesetzt wird.
Besonders relevant für ChatGPT sind die Anforderungen an Transparenz: Nutzer*innen müssen darüber informiert werden, dass sie mit einer KI interagieren und generierte Inhalte müssen als KI-erzeugt gekennzeichnet werden. OpenAI muss zudem technische Dokumentationen bereitstellen und ein Risikomanagement für das Modell implementieren.
Drei Tipps für den sicheren Umgang mit ChatGPT
Der sichere Umgang mit ChatGPT erfordert Bewusstsein für die Datenschutzrisiken und proaktive Maßnahmen. Mit diesen drei zentralen Tipps schützt du deine Privatsphäre und vermeidest rechtliche Fallstricke.
• Trainingsdaten ausschalten: Deaktiviere in deinen ChatGPT-Einstellungen, dass deine Gespräche zum Training zukünftiger KI-Modelle verwendet werden. Auf diese Weise reduzierst du das Risiko, dass vertrauliche Informationen in die falschen Hände geraten.
• Nutze nur Daten, für deren Verwendung du die Zustimmung hast: Lade niemals Bilder, Texte oder personenbezogene Daten Dritter ohne deren ausdrückliche Einwilligung hoch. Verwende notfalls anonymisierte Daten oder Pseudonyme, wenn du Beispiele oder Fallstudien mit ChatGPT bearbeiten möchtest.
• Keine Geschäftsgeheimnisse oder vertraulichen Informationen preisgeben: Behandle ChatGPT wie ein öffentliches Forum: Teile niemals Betriebsgeheimnisse, Patientendaten, vertrauliche Unternehmensinformationen oder andere sensible Inhalte. Führe gegebenenfalls auch interne Richtlinien für dein Unternehmen ein, an die sich deine Mitarbeiter*innen halten müssen.
Fazit: Viele Möglichkeiten, viele Risiken
ChatGPT bietet dir beeindruckende Möglichkeiten für deine tägliche Arbeit, birgt jedoch bei unbedachter Nutzung erhebliche Datenschutzrisiken. Die Preisgabe sensibler Informationen kann – wie der Samsung-Fall zeigt – zu folgenschweren Datenlecks führen, während die intransparente Datenverarbeitung dich in rechtliche Grauzonen manövriert.
Schütze dich daher aktiv durch Deaktivierung der Trainingsdatennutzung, Verwendung anonymisierter Informationen und strikten Verzicht auf die Eingabe von Geschäftsgeheimnissen oder personenbezogenen Daten Dritter.
