Inhalt
- Das Experiment: Sprachmodelle als persönliche Black Friday Shopping-Berater
- Die Kategorien: Wer dominiert, wer bleibt unsichtbar?
- Was Marken jetzt wissen müssen
- Die Sprachmodelle im Vergleich
- Wo und wie geben die Sprachmodelle ihr Spielgeld aus?
- Die große Erkenntnis: Wird LLMO zur Schlüsselstrategie der Zukunft?
- Warum könnte LLMO das neue Must-Have werden?
- LLMO: Wie fängt man damit an?
Hast du schon mal Sprachmodelle wie ChatGPT genutzt, um Produkte zu recherchieren oder auszuwählen? Laut Statista verwenden 10 % der Büroangestellten ChatGPT täglich – und bei 3,7 Milliarden monatlichen Besuchern weltweit wird der Einfluss solcher Tools immer größer. Kein Wunder also, dass Sprachmodelle nicht mehr nur ein Trend sind, sondern die Art und Weise verändern, wie wir Produkte entdecken, bewerten und kaufen. Aber wie kommen sie eigentlich zu ihren Empfehlungen? Und welche Produkte schlagen sie vor, wenn sie wie ein persönlicher Einkaufsberater genutzt werden? Zeit für ein Experiment!
"Hey, in einer Woche ist Black Friday und ich habe ein Budget von insgesamt 800 €. Kannst du mir bitte helfen, 5 Produkte aus 5 verschiedenen Kategorien auszuwählen? Einen Elektronikartikel, einen Modeartikel, ein Haushaltsgerät, einen Kosmetikartikel und ein Spielzeug für Kinder von 5–10 Jahren. Ich suche die besten Marken und guten Angebote, aber mein Gesamtbudget muss eingehalten werden. Welche Produkte kannst du mir also in jeder Kategorie empfehlen und warum? Danke!"
Die Ergebnisse waren überraschend: Sie zeigten nicht nur, welche Marken und Produkte bevorzugt wurden, sondern lieferten auch interessante Einsichten über die Funktionsweise von Sprachmodellen – von Markenpräferenzen und trendigen Produktkategorien bis hin zu amüsanten Rechenfehlern.
Diese Ergebnisse sind zwar nur eine Momentaufnahme aus der Woche vor dem Black Friday 2024, sie zeichnen jedoch ein klares Bild davon, wie Sprachmodelle Kaufentscheidungen priorisieren. Und: Sie verdeutlichen, welche Herausforderungen und Chancen diese Technologie für Marken mit sich bringt.
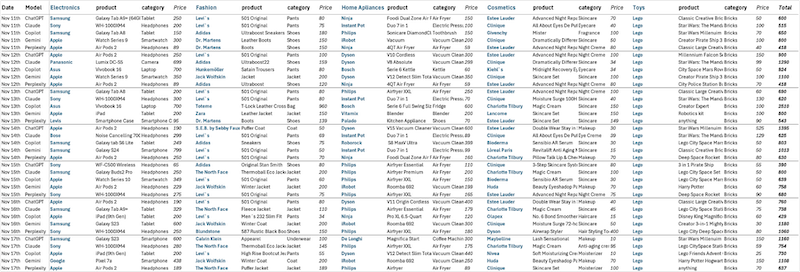
Zusammengefasst: 7 Tage, 5 Sprachmodelle, 5 Shopping-Kategorien, macht in Summe 175 Marken- und Produktempfehlungen samt Preis und Quellenangabe. Das reicht nicht für eine echte Marktstudie, aber ist eine schöne Momentaufnahme aus der Woche vor dem Black Friday 2024.
Es kann sein, dass die Ergebnisse bei dir etwas anders ausfallen, zudem kam Perplexity natürlich genau letzte Woche mit einer neuen, integrierten
Shopping Funktionalität heraus. Das Experiment hat daher nicht den Anspruch auf Wissenschaftlichkeit, sondern ist eine Snapshot, der zeigt, wie Sprachmodelle Kaufentscheidungen beeinflussen können und welche Herausforderungen und Chancen diese Technologie für Marken mit sich bringt.
Die Kategorien: Wer dominiert, wer bleibt unsichtbar?
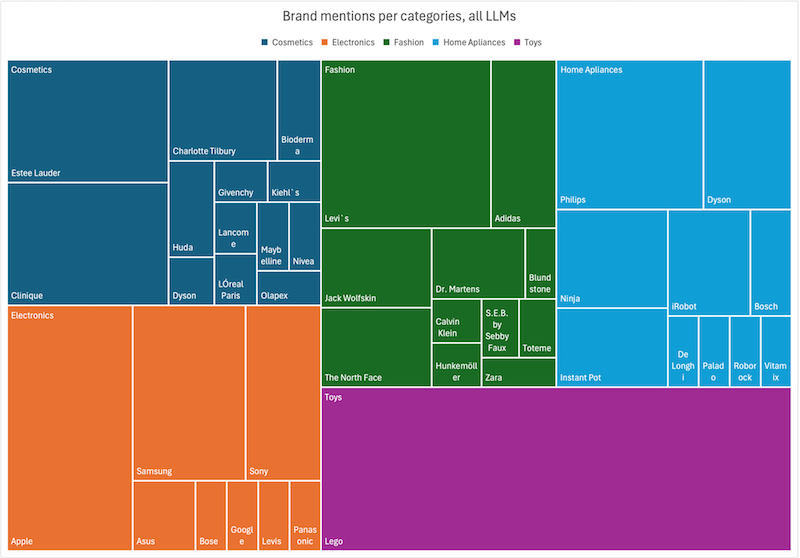
Elektronik: Apple und Samsung dominieren den Markt
In der Kategorie Elektronik dominierten Apple und Samsung die Empfehlungen mit großem Abstand: 40 % der möglichen Erwähnungen gingen an Apple, 26 % an Samsung. Die beliebtesten Produkte? Kopfhörer! Apples AirPods (2. Generation) und Sony WH-1000XM4 standen weit oben auf der Liste.
Auffällig war, dass Marken wie Bang & Olufsen, die bei traditionellen SEO-Suchanfragen oft sehr gut abschneiden, komplett ignoriert wurden. Das legt nahe, dass Sprachmodelle eher Bestseller priorisieren und weniger Wert auf Innovation oder Nischenprodukte legen.
Mode: Levi’s überrascht, Nike bleibt unsichtbar
Ein unerwarteter Gewinner in der Modekategorie war Levi’s – vor allem mit der klassischen Levi’s 501 Original Jeans. Sie wurde gleich mehrfach empfohlen. Dr. Martens und Adidas tauchten ebenfalls auf, wenn auch deutlich seltener.
Interessant: Große Namen wie Gucci, Prada oder Nike fehlten komplett. Eine solche Abwesenheit wäre bei einer klassischen Google-Suche undenkbar. Es zeigt, dass selbst globale Marken in den Algorithmen der Sprachmodelle nicht automatisch Sichtbarkeit genießen.
Ein kurioses Detail: Levi’s tauchte nicht nur in der Modekategorie auf, sondern wurde auch bei Elektronik empfohlen – mit Handyhüllen. Das zeigt, wie tief die Marke in den „Gedächtnissen“ der Modelle verankert ist.
Haushaltsgeräte: KI kann nicht essen, liebt aber Fritteusen
In der Kategorie Haushaltsgeräte gab es mehr Vielfalt. Dyson stach hervor, mit Produkten vom Staubsauger bis zum Haartrockner. Die heißeste Produktkategorie? Heißluftfritteusen! Philips und Ninja führten die Liste an.
Auch hier zeigte sich ein wiederkehrendes Muster: Bestseller wurden bevorzugt, während neuere oder innovativere Technologien – wie Smart-Home-Geräte – kaum berücksichtigt wurden.
Kosmetik: Clinique und Estée Lauder dominieren
In der Kosmetikkategorie kristallisierten sich Clinique (23 % der Empfehlungen) und Estée Lauder (26 %) als Spitzenreiter heraus. Andere Marken wie Maybelline oder Charlotte Tilbury wurden auch genannt, aber in deutlich geringerem Umfang.
Eine große Überraschung: Branchenriesen wie Nivea, die besonders in Deutschland sehr präsent sind, tauchten gar nicht auf. Das zeigt, dass Sprachmodelle weder globale Namen noch lokale Präferenzen automatisch bevorzugen.
Ein weiteres interessantes Detail: Der Dyson-Haartrockner tauchte auch hier auf und wurde in der Kategorie Kosmetik empfohlen – ein Zeichen dafür, dass Marken ihre Produkte erfolgreich in mehreren Kategorien positionieren können.
Spielzeug: Lego, Lego, Lego – und sonst nichts
Wenn es einen klaren Gewinner im Experiment gibt, dann ist es Lego. In der Kategorie Spielzeug erreichte die Marke ein beispielloses Ergebnis: Alle 35 möglichen Empfehlungen gingen an Lego. Andere Spielzeugmarken – von Playmobil über Fisher-Price bis hin zu Schleich – wurden überhaupt nicht erwähnt.
Dieses Ergebnis zeigt, dass Lego für Sprachmodelle nahezu synonym mit „Spielzeug für Kinder von 5 bis 10 Jahren“ ist. Eine Frage an die Marketingmanager der Konkurrenz: Ist euch das bewusst? Die finanzielle Hebelwirkung dieser Wahrnehmung könnte enorm sein.
Besonders spannend: Innerhalb des Lego-Portfolios gab es viel Abwechslung. Die Modelle empfahlen 20 verschiedene Lego-Sets, vom Star Wars Millennium Falcon bis zu Harry Potter und Lego City. Das zeigt, wie breit Lego bei den Sprachmodellen verankert ist.
Was Marken jetzt wissen müssen
Mal ehrlich: Damit haben wir nicht gerechnet. Die Empfehlungen der Sprachmodelle waren – gelinde gesagt – ziemlich uninspiriert. Standardvorschläge, die vor allem den Durchschnittskäufer oder den „sicheren Mittelweg“ ansprechen. Keine Spur von Mut, Innovation oder Luxus. Stattdessen setzten die Modelle stark auf Markentreue: Dominierende Anbieter in jeder Kategorie wurden bevorzugt, während kleinere oder exklusive Marken kaum eine Chance hatten.
Und, was denkst du? Klingt das nach den Vorschlägen, die deine Marke spannend machen würden?
Wie die Sprachmodelle wirklich ticken
Jetzt wird’s spannend: Wir haben uns die Ergebnisse genauer angesehen und sind tiefer eingestiegen. Neben den bevorzugten Marken und Produkten haben uns zwei Fragen besonders interessiert:
- Wie verteilen die fünf Modelle ihr Budget auf die verschiedenen Kategorien?
- Halten sie sich überhaupt an die vorgegebenen 800 Euro?
Außerdem wollten wir wissen, auf welche Quellen sich die Modelle stützen. Die Analyse zeigt klar: Die Art, wie Sprachmodelle ihr Budget verwalten und woher sie ihre Empfehlungen nehmen, kann dir wichtige Insights liefern
Die Sprachmodelle im Vergleich
OpenAI ChatGPT: Der verlässliche AllrounderChatGPT lieferte eine ausgewogene Mischung aus bekannten Marken und Produkten. Es zeigte nur wenige Budgetüberschreitungen und war im Vergleich zu den anderen Modellen gründlich bei der Angabe von Quellen. Trotz seiner Verlässlichkeit fehlte es ChatGPT jedoch an Kreativität oder Überraschungsmomenten.
Claude: Der ethische SkeptikerClaude weigerte sich zunächst, am Experiment teilzunehmen, da es den Black Friday aus ethischen Gründen ablehnt. Später machte das Modell dennoch mit und bot überwiegend Bestseller an. Es zeigte sich zuverlässig, aber wenig überraschend.
Zudem basierten Claude´s Empfehlungen, laut dessen Angabe, auf Daten bis zum Juni 2024, was es aber nicht davon abhielt, sehr überzeugte Empfehlungen abzugeben: „Das ist der beste Kopfhörerdeal.“ In Summe bot Claude ein etwas verwirrendes Verhalten, und Shopping-Assistenz zählt sicher nicht zu seinen Vorzeige-Use-Cases.
Microsoft Copilot: Mathe? Schwierig!Copilot fiel durch wiederholte Rechenfehler und Budgetüberschreitungen auf. Seine Empfehlungen waren stark auf Bestseller ausgerichtet, aber das Modell zeigte Schwächen bei der Budgetverwaltung und den Quellenangaben.
Google Gemini: Treu, aber monotonGemini war das markentreueste Modell und wiederholte häufig dieselben Marken und Produkte. Es bot wenig Abwechslung und hatte Probleme mit Budgetüberschreitungen und Berechnungsfehlern.
In Summe bot Gemini so ein recht schwaches Bild. Man hatte nie das Gefühl dass einem hier wirklich geholfen werden soll, und selbst nach Hinweis wurden Mathefehler nicht korrigiert.
Perplexity: Der Budgetmeister (und künftige „Pro-Shopper“?)Perplexity war das einzige Modell, das das Budget konsequent einhielt. Seine Empfehlungen waren solide und deckten eine größere Quellenvielfalt ab, waren aber nicht besonders innovativ.
Aktuell und spannend: Perplexity hat in der letzen Woche einen neuen KI-generierten Shopping Assistenten "Shop like a Pro" gelaunched. Mit dem neuen Feature möchte Perplexity den Checkout von Produkten im Chat möglich machen, man soll also gar nicht mehr bis zum Händler oder zum Markenshop weiter, ein radikaler Angriff auf Affilliate Modelle und definitiv die spannendste Neuerung der Sprachmodelle mit Blick auf das Experiment.
Wo und wie geben die Sprachmodelle ihr Spielgeld aus?
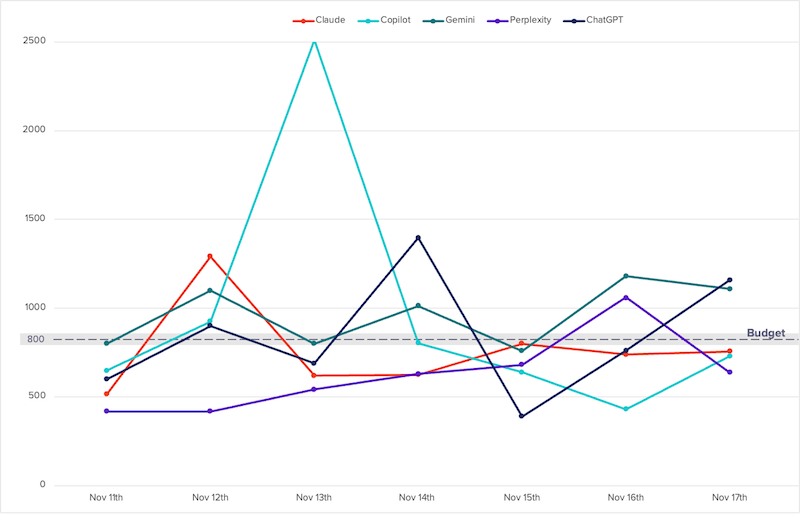
Es ist auch spannend zu beobachten, wie die Modelle ihre Budgets auf die verschiedenen Kategorien aufteilen. Im Experiment hat ChatGPT beispielsweise Haushaltsgeräte stärker priorisiert als andere Modelle und einen größeren Anteil seines Budgets in diese Kategorie investiert, während es Mode oder Kosmetik weniger Beachtung geschenkt hat. Gemini hat das zugewiesene Budget nicht wirklich interessiert und war an den meisten Tagen deutlich drüber, vielleicht auch wegen seiner schlechten Mathematikfähigkeiten. Perplexity hat das Budget von allen Modellen am ausgewogensten über die 5 Kategorien verteilt.
Die große Erkenntnis: Wird LLMO zur Schlüsselstrategie der Zukunft?
Neben den teils amüsanten Ergebnissen zu Sprachmodellen, Budgets und Marken sticht eine zentrale Erkenntnis aus dem Experiment hervor: Marken scheinen noch keine Strategie gefunden zu haben wie sie mit Sprachmodellen umgehen. Die Ergebnisse des Experiments zeigen deutlich, dass Marken dringend eine neue Form der Optimierung adaptieren müssen: LLMO – Large Language Model Optimization.
Im Gegensatz zu SEO (Search Engine Optimization), das auf Sichtbarkeit bei Google oder Bing abzielt, geht es bei LLMO darum, in den Empfehlungsalgorithmen von Sprachmodellen präsent zu sein. Ein komplett neues Feld, das noch nicht beschrieben ist, aber daher auch eine riesen Chance.
Warum könnte LLMO das neue Must-Have werden?
Setzen wir das mal ins Verhältnis. Stellen wir uns vor 4 Millionen Menschen nutzen Sprachmodelle für ihre Black-Friday-Recherche und folgen möglicherweise deren Empfehlungen. Wenn der durchschnittliche Warenkorbwert bei 250 € liegt, sprechen wir über einen gesamten wirtschaftlichen Wert von 1 Milliarde EUR während einer Black-Friday-Woche. Mit Blick auf die Nutzerzahlen von ChatGPT ist das eine sehr konservative Schätzung. Für Deutschland könnte man den Total Economic Value vielleicht bereits mit 10 multiplizieren, und für die USA vielleicht mit 50. Marken, die in den Algorithmen der Sprachmodelle also schlecht abschneiden, laufen Gefahr, unsichtbar zu werden und den direkten Zugang zu einem riesigen Markt zu verlieren. Die Einsätze sind enorm.
LLMO: Wie fängt man damit an?
Aber wie können Marken jetzt vorgehen? Dieses Feld steckt noch in den Kinderschuhen, doch durch eine erste Analyse der Quellen, auf die Sprachmodelle zurückgreifen, können wir beginnen, sinnvolle Strategien für LLMO zu skizzieren. Hier 3 Tipps wie Ihr mit LLMO starten könnt:
- Prominent auf den wichtigsten internationalen Händlerplattformen vertreten sein: Von Media Markt bis Walmart oder ToysRUs – Die Sprachmodelle gaben internationale Händler als ihre #1 Quelle an.
- Regelmäßig auf führenden Technik- und themenspezifischen Blogs erwähnt werden: Von Techradar bis Wired oder GQ – Magazine und Blogs mit Artikeln zu „Top 10 Black Friday Deals“ wurden auch gerne zitiert.
- Produktlinien und Kategorien klar als dominant in Euren Bereichen positionieren: Sprachmodelle mögen exakten Wortlaut. Viele Quellen spiegelten unsere Frage sehr genau wider, z.B. das Wort „Home Appliances“ oder „800 Eur“.
Wie zu Anfangszeiten des SEO gibt es für LLMO noch keine best practices. Marken, die jetzt beginnen in das Thema zu investieren haben daher eine große Chance. Konsumenten ändern ihre Wege, Kaufentscheidungen zu treffen – und Sprachmodelle werden zu einem Schlüsselfaktor. Sie übernehmen zunehmend die Rolle traditioneller Suchmaschinen, und mit ihnen ändern sich die Spielregeln. Wer nicht frühzeitig in LLMO investiert, wird Mühe haben, in der neuen Welt des digitalen Shoppings relevant zu bleiben. Bleibt also nur noch eine Frage: „SEOst du noch – oder LLMOst du schon?“




